


The secret behind Google's immense popularity is its cutting-edge algorithms that revolutionize the way we search. According to Google, the algorithms undergo hundreds of updates annually, ensuring unparalleled timeliness and accuracy in search results.
Part of Google's ever-evolving technology includes the use of Googlebots. They are web crawlers that collect information and create a searchable index of the internet. They include both mobile and desktop crawlers, as well as specific crawlers for news, images, and videos.
What is Googlebot Crawling and Why Is It Important?
Googlebot crawling is the process by which Google’s web crawler scans and indexes content from websites across the internet. This process is crucial because it helps search engines understand what your website is about, making it possible for your pages to appear in search results. Effective crawling ensures that your content is accessible to users searching for relevant information, which is key to driving traffic and increasing your website's visibility.
How the Google Crawler Works
The Googlebot crawler is a tool used by Google to discover and index web pages across the internet. It systematically scans websites, following links from one page to another, and gathers information about the content on each page. This information is then stored in Google’s index, making it accessible for search queries.
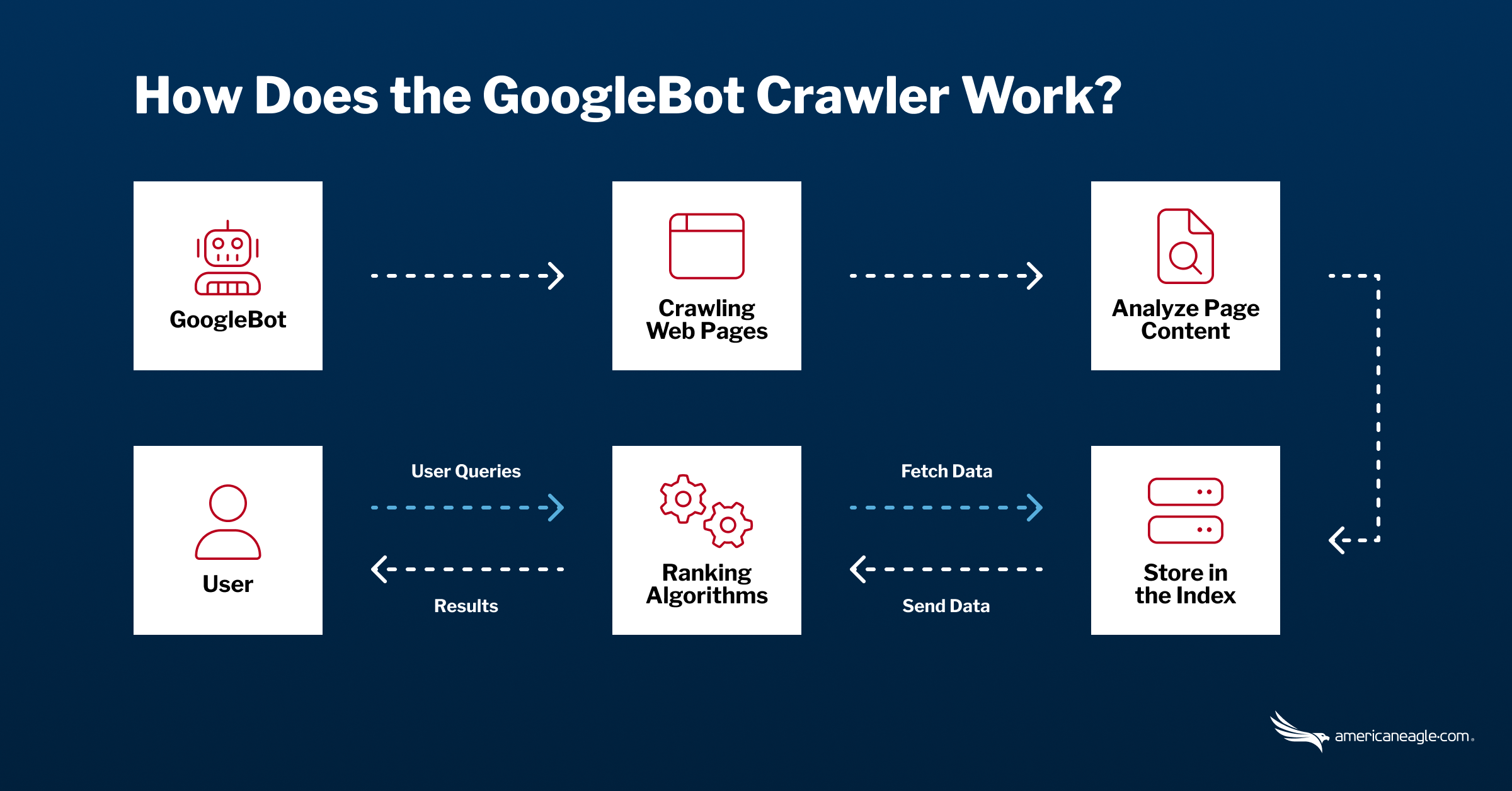
Googlebot Types and Functionality
Googlebots are crucial for SEO as they "read" web pages and index them so they can be served to searchers in response to their queries. There are several types of Googlebots, each with its specific functionality.
Mobile Crawler
The purpose of the Mobile Crawler is, well, what you’d think! It specifically targets mobile-friendly content to ensure that Google provides relevant and useful search results for users accessing the web through mobile devices. It’s a reflection of the growing usage of mobile devices for internet access.
Desktop Crawler
The Desktop Crawler is designed to simulate the view of a traditional desktop web browser. This enables Googlebot to understand and index web pages in a way similar to how a desktop user would experience them, ensuring that content and layout optimized for larger screens are properly indexed.
Specialized Crawlers
Googlebot uses Specialized Crawlers to gather information from specific types of websites and content. From news articles to images, videos, and local business listings, these crawlers are designed to dive deep into every niche. By leveraging the power of specialized crawlers, Google enhances its understanding and indexing of the internet, with the goal to deliver higher-quality and more relevant search results for you.
News Crawler
One specialized crawler targets and indexes content from news websites, focusing on articles and current events. This one is aptly named the “News Crawler” and it helps in populating and updating Google News with the latest information.
Images Crawler
Crawling the depths of the internet, the Images Crawler uncovers and organizes captivating images for Google's search engine. With its sole purpose of locating and categorizing pictures based on their relevance and exceptional quality, it ensures that only the best visuals make it into the search results, improving Google Image Search.
Video Crawler
Video crawlers are specialized bots that scour the internet for video content. They extract all the important details like titles, descriptions, and tags from videos. This means Google can present you with truly relevant, comprehensive, and high-quality videos when you search.
Googlebot User Agent Strings
Each type of Googlebot crawler identifies itself with a unique user agent string. These strings provide information about the bot to the server, including its name and version. They are used when Googlebot makes a request to crawl the content on a website, and there are several variations of Googlebot User Agent Strings, each serving a different function or targeting a different type of device. For example, the User Agent String for Googlebot on mobile devices is different from the one used for desktops. They’re beneficial because they allow webmasters to tailor responses or optimizations specific to the type of crawler accessing their website.
Googlebot as an Evergreen Browser
It’s important to note that Googlebot operates as an evergreen browser. It views and interacts with websites as a user would in the latest version of the Chrome browser, ensuring that Googlebot can accurately process modern web technologies and dynamic content, leading to a more accurate and up-to-date representation of the web in Google's search index.
The Mission of Googlebot
Googlebot’s mission is to discover, analyze, and index content from across the web to provide users with the most relevant and useful search results. By continuously crawling websites, Googlebot ensures that search engine results are up-to-date and reflect the latest information available. To help Googlebot achieve its purpose, it’s important to make your site easily navigable, with clear structure and relevant content, so that it can efficiently index your pages. Proper optimization of your site enhances its visibility and helps ensure that your content reaches the right audience through search engines.
Googlebot's Crawling and Indexing Process

In the world of Google, the journey to uncover valuable information involves two crucial steps: crawling and indexing. When Googlebot sets out on its mission, it starts by grabbing a handful of web pages. Following the links on those pages, it ventures into the vast expanse of the internet, unearthing new URLs and expanding its reach.
Once the crawling phase is complete, Googlebot dives into the next stage: indexing. The data collected from the web pages is skillfully processed and organized into a comprehensive index. Just like a browser renders code, the bot diligently examines the content, including videos, images, and articles, and stores them for easy access. Through these meticulous steps, Google optimizes its search engine, ensuring that valuable information is readily available at your fingertips.
Operational Scale and Efficiency of Googlebot
Googlebot drives operational scale and efficiency by utilizing the following:
- Distributed crawling system: Googlebot operates on thousands of machines, forming a vast distributed network.
- Adaptive crawling speed: The system dynamically adjusts the crawling rate to ensure website performance is not adversely affected.
- Balancing act in web crawling: Googlebot is programmed to balance its crawling activities, ensuring comprehensive indexing without overwhelming server resources.
The Crawling Process of Googlebot
The crawling process of Googlebot involves three main components:
- Discovering web content: Googlebot begins its process by discovering URLs through sitemaps and existing links.
- Following links: It crawls the web by following links from one page to another.
- Frequency and depth of crawling: The frequency and depth of crawling depend on factors like page importance, freshness, and site architecture.
Indexing Strategy by Googlebot
Once the crawling process is complete, the indexing strategy by Google is implemented. This involves:
- Identifying changes and updates: Googlebot constantly looks for new, updated, or changed content on web pages.
- Handling new links: New links discovered during crawling are added to Google's list of URLs to be crawled.
- Content storage and accessibility: The content from rendered pages is stored in Google's index, making it searchable for users.
Making Web Content Searchable
To make web content searchable, Google takes the crawled data and processes and converts it into a format suitable for storage in the search index. The indexed content is later used to respond to user queries, with relevance and ranking determined by Google's algorithms. Finally, Googlebot's ongoing crawling and indexing efforts ensure that Google's search index remains comprehensive and up-to-date.
Controlling Googlebot's Activity
Controlling Googlebot's activity mainly involves managing its crawl rate and specifying which pages you want it to index or not. Please note that controlling Googlebot's activity should be done carefully, as improper configurations can prevent Googlebot from crawling and indexing your site properly, which could impact your site's presence in search results.
Here are some ways Googlebot's interaction can be controlled:
Using robots.txt to Control Access
You can use a robots.txt file to control how Googlebot accesses your site. This file tells Googlebot which pages or sections of your site it can or cannot crawl. The implementation of robots.txt involves placing it in the root directory of a website, specifying which parts of the site should be excluded from crawling.
Implementing Nofollow Attributes
A tag, Nofollow Link Attribute, can be added to hyperlinks to indicate that Googlebot should not follow the link. While it's considered a hint rather than a directive, it generally guides Googlebot away from certain links.
Adjusting Googlebot's Crawl Rate
If Google's crawl rate is overwhelming your server, you can reduce the crawl rate. This can be done via the Google Search Console by adjusting the speed at which Googlebot crawls the site. This is useful for managing server load, ensuring the site's performance is not hindered by crawling activities.
Deleting Content to Remove from Index
Another way to control Googlebots would be to remove or delete a page from a website search result so it’s removed from Google's index. This is a permanent solution for content you no longer wish to be indexed or accessed.
Restricting Access to Control Indexing
Utilizing password protection or authentication methods to block Googlebot from accessing certain content is an effective way to keep private or sensitive content out of Google's index.
Utilizing Noindex Tags
Noindex Meta Tags can be placed in the HTML of a page to indicate that it should not be indexed. Unlike robots.txt, however, a noindex tag directly instructs Googlebot to exclude the page from the search index.
URL Removal Tool for Temporary Hiding
You can also use Google's URL Removal Tool, a feature in the Google Search Console that allows you to temporarily hide URLs from search results. It's important to note that this tool, unlike deleting content, does not permanently remove a URL from the index but hides it temporarily.

Googlebot FAQs
What is Googlebot and How Does it Work?
Googlebot is the web crawling bot used by Google to gather information from webpages to add to Google's searchable index. It works by following links from one page to another to discover content.
How Does Googlebot Discover New Webpages?
Googlebot finds new webpages through links from existing pages in its index. Also, website owners can directly submit new pages or sitemaps to Google for indexing.
What is the Difference between Crawling and Indexing?
Crawling is the process where Googlebot visits and reads new and updated webpages, and Indexing is the process of adding and organizing the content found during crawling into Google’s index for quick retrieval in search results.
How Often Does Googlebot Crawl Websites?
Popular and regularly updated websites may be crawled more frequently, but Googlebot crawling varies based on factors like the size of the website, the frequency of content updates, and the website's overall health.
Can Website Changes Affect How Googlebot Crawls a Site?
Changes like updating content, altering the site structure, or improving mobile friendliness can affect how Googlebot crawls a site and these changes can make the site more crawl-efficient and potentially improve its indexing.
How Can Webmasters Optimize Their Sites for Googlebot?
Webmasters can optimize their sites for Googlebot by using SEO-friendly URLs, having a clean, clear site structure, improving page load times, making the site mobile-friendly, and using the robots.txt file and sitemaps effectively.
What are Common Issues Websites Face with Googlebot Crawling and How Can They Be Fixed?
Some of the most common issues include crawl errors, broken links, and slow loading times. These can be fixed by using tools like Google Search Console to identify and rectify errors, having a good hosting environment, and maintaining website health.
How Does Googlebot Handle JavaScript and Dynamic Content?
It's more complex than crawling static HTML, but Googlebot can process JavaScript and dynamic content. It’s important to make sure that the JavaScript content is accessible and not blocked by robots.txt files.
What is the Role of Robots.txt in Controlling Googlebot's Crawling?
The robots.txt file is a way to control Googlebot’s crawling by telling Googlebot which pages or sections of a site should not be crawled. This is crucial for directing the bot's activity and ensuring it doesn't access sensitive or irrelevant areas.
How Does Googlebot Impact SEO and Search Engine Rankings?
Since Googlebot's crawling and indexing are foundational to SEO, a site that's easily crawlable and indexable is more likely to be ranked higher in search results. By optimizing your site's content and structure, you can ensure that Googlebot not only understands your website but also prioritizes it among the top search results.
Unleash Your Website's Full Potential with Our Expert SEO Services!
Are you looking to rank your website at the top of Google's search results? Americaneagle.com’s team of SEO experts is here to help. We specialize in creating strategies that are perfectly aligned with how Googlebot crawls and indexes content. Whether it's improving mobile responsiveness or optimizing your site's structure, we cover every aspect to ensure your online presence gets the attention it deserves.
To learn more call (877) 932-6691 or fill out the contact form.





